Application of machine learning in rheumatic disease research
Article information
Abstract
Over the past decade, there has been a paradigm shift in how clinical data are collected, processed and utilized. Machine learning and artificial intelligence, fueled by breakthroughs in high-performance computing, data availability and algorithmic innovations, are paving the way to effective analyses of large, multi-dimensional collections of patient histories, laboratory results, treatments, and outcomes. In the new era of machine learning and predictive analytics, the impact on clinical decision-making in all clinical areas, including rheumatology, will be unprecedented. Here we provide a critical review of the machine-learning methods currently used in the analysis of clinical data, the advantages and limitations of these methods, and how they can be leveraged within the field of rheumatology.
INTRODUCTION
Machine learning (ML) is a field of computer science that aims to create predictive models from data. It makes use of algorithms, methods and processes to uncover latent associations within the data and to create descriptive, predictive or prescriptive tools that exploit those associations [1]. It is often related to data mining [2], pattern recognition [3], artificial intelligence (AI) [4], and deep learning (DL) [5]. Although there are no clear definitions or boundaries among these areas and they often overlap, it is generally agreed that DL is a more recent sub-field of ML that uses computationally intensive algorithms and big data [6] to capture complex relationships within the data. Using multi-layered artificial neural networks, DL has dramatically improved the state-of-the-art in a variety of applications, including speech and visual object recognition, machine translation, natural language processing, and text automation [5,7]. Similarly, AI is broader than ML in that it uses the latter as a prediction engine feeding decision support and recommendation systems that are more than the sum of their parts. AI has been around for more than 70 years, born out of our appreciation and admiration of the power and inner workings of human intelligence [8]. Moreover, ML and AI are already part of our everyday lives, as they underlie our web searches [9], e-mail anti-spam filters [10], hotel and airline bookings [11], language translators [12], targeted advertising [13], and many other services [14]. Lately, ML and AI have captured the world's imagination in applications involving various complex games, with one of the most celebrated cases being the GO match held in 2016 between Sedol Lee, one of the top GO players in the world, and the computer program AlphaGo [5]. Fig. 1 provides a grouping of the different fields related to ML and AI.
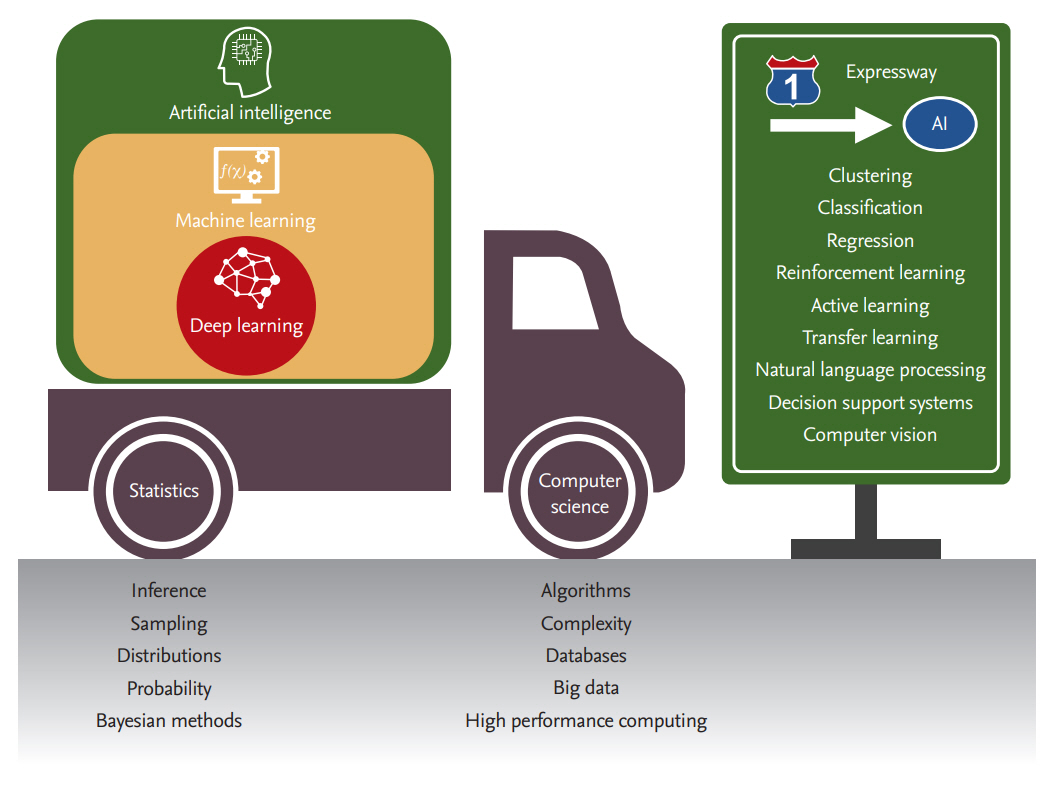
An overview of fields related to learning from data. AI, artificial intelligence.
The concept of ML dates to the 1940s but its development since the 1990s has been rapidly accelerated by the confluence of four key factors: the digitalization and storage of a massive amount of high-dimensional data at low cost; the development of general and graphic processors with high computational power; breakthroughs in ML algorithms that have significantly improved performance and minimized errors; and the free availability of open-source tools, codes, and models. In a clinical setting, ML and AI tools can help physicians ton understand a disease better and more accurately evaluate patients’ status based on high-throughput molecular and imaging techniques, which at the same time reveal the complexity and heterogeneity of the disease [15-17]. Nonetheless, equal to the promise of ML/AI are the potential dangers that may arise if too much trust is placed in automated diagnosis and decision tools. As a cautionary tale, the concordance between IBM’s Watson for Oncology [18] and an expert board of oncologists was highly variable, with a range of 17.8% to 97.9% depending on the tumor type, stage, hospital, and country [19]. Moreover, in recent news, the tool reportedly recommended unsafe cancer treatment plans [20]. Therefore, a thorough understanding and judicious approaches to ML are required to ensure its reasonable use in research and clinical practice. This is especially apparent given the complex nature of medicine, which involves the interactive combination of clinical and biological features in disease manifestation and diagnosis; a continuous inflow of new medical tools and drugs; socio-economic factors, such as the permission to treat that must be obtained from insurance companies; drug regulation and release by the regulatory agencies of the various countries; and ethical issues dealing with the use of electronic medical records (EMRs).
Rheumatic diseases, including rheumatoid arthritis (RA), systemic lupus erythematosus, Sjögren’s syndrome, systemic sclerosis, idiopathic inflammatory myositis, and the systemic vasculitides, are chronic autoimmune inflammatory disorders with multi-organ involvement. Complex interactions between a multitude of environmental and genetic factors affect disease development and progression [21,22]. In view of their heterogeneity, most rheumatic diseases are not defined as a single entity but as a single group according to established classification criteria [21,22]. Previous risk-prediction models for disease development and outcome based on population-wide databases work well on average, but in terms of precision medicine many of the diagnostic and management needs of patients with rheumatic diseases are still unmet [23,24]. In this setting, ML can suggest effective solutions for the unsettled issues arising from complex and heterogeneous diseases such as rheumatic diseases [16]. ML applications in multi-omics datasets were examined in detail in a series of recent reviews [7,25-29], and the superb performance of DL in image analysis has been the focus of recent papers [30-33]. Here we review the core principles and processes of ML that are applicable to clinical medicine as well as the current use of ML in research on rheumatic diseases. Our aim is to help clinicians and rheumatologists to understand better the basics of ML and its relevant research applications.
THE BASICS OF MACHINE LEARNING
Differences from traditional statistical models
There are substantial differences between ML and traditional statistics. First, ML concentrates on the task of “prediction,” by using general-purpose learning algorithms to find patterns in often rich and unwieldy data. By contrast, statistical methods have a long-standing focus on inference, which is achieved through the creation and fitting of a project-specific probability model [34]. Second, most ML techniques are hypothesis-free, as their aim is to reconstruct associations within the data, whereas traditional statistics usually rely on specific assumptions and hypotheses, often those stemming from the model that has generated the data [35]. Third, the toolsets used to evaluate the generalization errors of an ML model (receiver-operating characteristic curves, cross-validation, among others) are generally different from those of traditional statistical techniques, which mostly rely on a calculation of the p value to reject a null hypothesis [34,36,37]. Fourth, traditional statistical modeling is generally fitted to produce the simplest, most parsimonious model and yields a result that is easy to understand and interpret. However, clinical and biological factors are usually not independent of each other and their associations may be non-linear. ML approaches, however, consider all possible interactions between variables according to multi-dimensional non-linear patterns, irrespective of the degree of complexity, while aggressively seeking to capture as many informative and interesting features as possible. Nonetheless, by the same token, this can produce a complicated and sophisticated model that is not easy to understand or interpret. Fifth, it is often the case that the results of clinical studies are not consistent across studies, due to differences in the characteristics of the study population, the sample size or the measured variables (number, scale, and method). This is partly because traditional models seek a goodness of fit in a set of study samples. By contrast, the fundamental goal of ML is to generalize beyond the examples in the training set. Generalization is feasible because the models derive from a much larger dataset, are then validated in an independent dataset and further tuned to obtain the best performance [38,39].
Types of machine learning
There are many types of ML algorithms, as shown in Fig. 2. One of the most widely used categorizations separates them into three classes: supervised, unsupervised, and reinforcement learning.
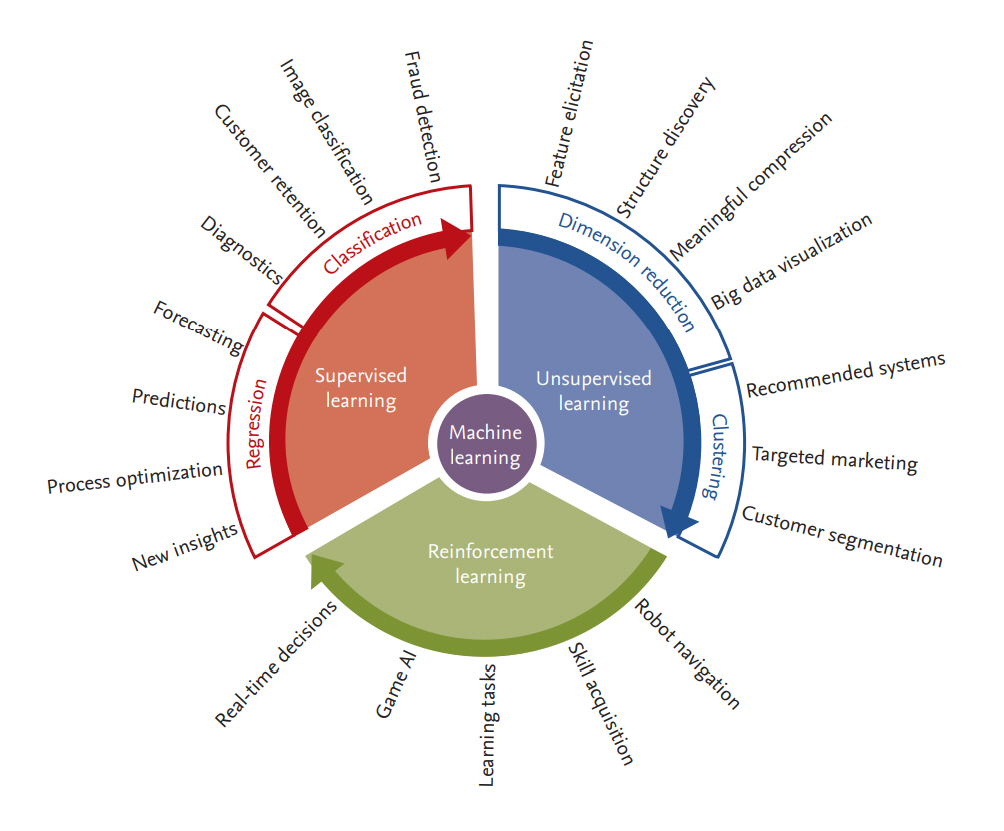
Overview of categorical types and different machine-learning algorithms. AI, artificial intelligence.
Supervised learning
Supervised learning searches for the relationship between a set of features (input variables) and one or more known outcomes (output classes or labels) and then derives a function that predicts the output value for a set of unlabeled input values based on an acceptable degree of fidelity [17,36,37]. For supervised learning to work, the training data should have the correct input-output pairs, which should be labeled by experts. Supervised learning includes both classification, where the task is to predict the group or class to which a new sample should be assigned (hence the output is a discrete variable), and regression, where the value of a continuous variable for a new sample must be estimated. For example, to determine whether a set of clinical features can predict the treatment response in patients with RA treated with a specific therapy, researchers can apply a supervised learning algorithm to a dataset in which each patient record contains the set of clinical features of interest and a label specifying the degree of disease responsiveness (e.g., “good,” “moderate,” “no” response, in conformity with the EULAR response criteria) [40]. Supervised learning algorithms include logistic and linear regression, naïve Bayesian classifiers, decision trees and random forests, support vector machines (SVMs), k-nearest neighbors, and neural networks [17,36,37].
Unsupervised learning
Unsupervised learning is a sub-field of ML that attempts to identify the structure in the data without the need for a training set, classes, or labels [17,36,37]. In the medical field, an example would be to identify hidden subsets of patients with similar clinical or molecular characteristics as described in the data. For example, patients with diffuse-type systemic sclerosis can be further categorized as having inflammatory, fibroproliferative, or normal-like disease based on their skin’s molecular signature [41,42]. The significance of this additional grouping can be further evaluated by determining correlations with clinical features and performance in subsequent supervised learning tasks. Unsupervised learning algorithms include clustering methods such as hierarchical or k-means clustering, principal component analysis, t-distributed stochastic neighbor embedding (t-SNE), non-negative matrix factorization, and latent class analysis [17,36,37,43].
Reinforcement learning
Reinforcement learning is an area of ML that is based on behavioral psychology, namely, how software agents take actions in a particular environment to maximize the cumulative reward [39]. The best example is game theory and the above-mentioned AlphaGo, which places a stone at a specific position on the board at a certain point in the game to maximize the winning rate [44]. A similar method was also used to select the best initial time for second-line therapy in patients with non-small cell lung cancer [45]. However, although it has great potential, reinforcement learning is not often applied to clinical settings, as it needs rigorously defined clinical states, observations (vitals, lab results, among others), and actions (treatment) and rewards, which are quite difficult to define and are sometimes unknown.
Transfer learning
Transfer learning is the improvement of the learning of a new task through the transfer of knowledge from a related task that has already been learned [46]. The assumption is that a model pre-trained in a dataset that has some similarities with the final dataset, i.e., the one that will ultimately be used for training, will perform better and be trained faster than if the model is exposed only to the latter. The two conditions under which this assumption holds true are: (1) the final dataset is much smaller than what is dictated by both the task at hand and the complexity of the model and (2) the pre-training dataset and the final dataset have some commonalities that are informative for that task. For example, assume that a model is to be trained to recognize black swans in images but only a few dozen images of swans of any kind are available; hence, the dataset is sufficient to train only the simplest of neural networks. In an alternative approach, large datasets comprising hundreds of thousands of images of birds in general can be substituted to pre-train the classifier to recognize birds. This pre-trained “bird” classifier can then be taught, using the key informative features of a bird (feathers, wings, beak, etc.), to recognize black swans from other items, including other birds. In a more relevant study for clinicians, Lakhani and Sundaram [47] adopted two famous deep convolutional neural network (DCNN) models for image classification, AlexNet [48] and GoogLeNet [49], pretrained on ImageNet [50], to differentiate pulmonary tuberculosis from the normal condition on a simple chest radiograph. DL with a DCNN accurately classified tuberculosis with an area under the curve (AUC) of 0.99.
SALIENT POINTS TO CONSIDER WHEN RUNNING MACHINE LEARNING
Medical or healthcare data can be presented in a table consisting of two components: rows of samples (observations or instances) and columns of features (variables or attributes). A schematic diagram of a supervised ML process is provided in Fig. 3. In data science, a programmed machine or model type is called a “learner.” In the following we discuss several points that should be kept in mind when ML is used.
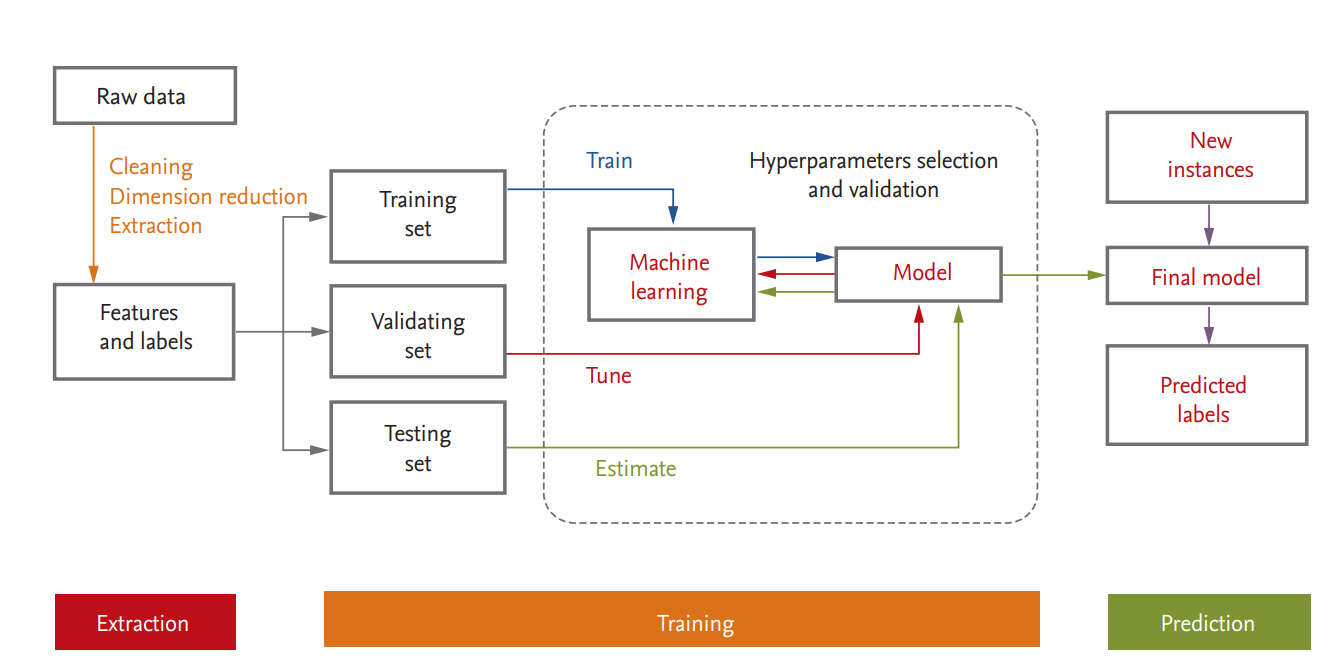
Workflow to develop a supervised machine-learning-based predictive model.
Data quantity, quality, and their control
In ML, the data are of high dimensionality and the sample size is large, so-called Big Data. An exploration of each subgroup of the data can reveal hidden structures by extracting important common features across many subgroups even when there are large individual variations. This is not feasible when the sample size is small because outliers may be mistakenly identified [51]. However, Big Data, a term applicable to EMRs, are inevitably characterized by certain weaknesses [51-53]. High dimensionality brings noise accumulation, spurious correlations, and incidental endogeneity [51]. In addition, because the massive samples in Big Data are typically aggregated from multiple sources at different times using different technologies, issues of heterogeneity, experimental variation, and statistical bias arise. Medical data are no exception, as there are clear differences between the formats used in EMRs, laboratory instruments, scales, assay reagents, and laboratory data notation methods. Furthermore, clinical and laboratory elements are often recorded incompletely or according to the preference of the particular doctor and therefore differently. In fact, the accuracy, completeness and comparability of EMR data were shown to vary from element to element by 10% to 90% [54]. The same disease code may be differently defined depending on the updated criteria, and coding errors inevitably occur because for the most part humans perform the recording. According to the Korean National Health Insurance claims database, true RA made up 91.4% of the total RA disease codes based on the RA identification algorithm [55]. Hence, to handle these challenges, aggressive quality control is needed [56], including data cleansing and refining techniques, such as error correction, removal of outliers, missing data interpolation, normalization, standardization, and de-batching. However, these processes rely on expert human judgment. Since even complex and sophisticated algorithms will not produce good results if the quality of the input data is poor, refinement of input data to improve their quality will provide better results even if the algorithm is less than optimal [37,57]. As has often been noted: “garbage in, garbage out” [58].
Data preprocessing
Raw data are usually not in a structure that is convenient for researchers to work with and not organized enough to be ready for ML. Data preprocessing refers to any transformation of the data before a learning algorithm is applied. It includes example finding and resolving inconsistencies; imputation of missing values; identifying, removing, or replacing outliers; discretizing numerical data or generating numerical dummy variables for categorical data; dimensionality reduction; feature extraction/selection; and feature scaling (normalization, standardization or Box-Cox transformation) [59]. Of these, feature scaling through standardization (or Z-score normalization) is an important preprocessing step for many ML algorithms. Predictor variables with ranges of different orders of magnitude can exert a disproportionate influence on the results. In other words, in the context of an algorithm, predictor variables with a greater range of scale may dominate. The scaling of feature values implicitly ensures equal weights of all features in their representation and should be the applied preprocessing approach in ML algorithms such as linear regression, SVM, and k-nearest neighbors [37].
Training, validation, and test datasets
For ML, the data are usually split into training, validation, and test datasets. The training dataset is the data sample used to fit the model. The validation dataset is the data sample used to provide an unbiased evaluation of a model fit on the training dataset while tuning model hyperparameters; it is regarded as a part of the training set. The test dataset is the data sample used to provide an unbiased evaluation of the fit that the final model achieved with the training dataset [36,37,60]. If the categorical variables are unbalanced, stratified sampling is favored. When a large amount of data is available, each set of samples can be set aside. However, if the number of samples is insufficient, removing data reduces the amount available for training. This can be mitigated by the use of resampling methods such as cross-validation and bootstrapping [60,61]. In general, a repeated 10-fold cross validation is recommended because of the low bias and variance properties of the performance estimate and the relatively low computational cost [37].
Bias-variance trade-off and overfitting
ML methods are often hindered by bias-variance trade-offs when a high-dimensional dataset with an inadequate number of samples is to be fitted [36,37,61]. Bias is the training error of the model; that is, the difference between the prediction value and the actual value. Models with a high bias tend to underfit, by applying a simpler model to describe a dataset of higher complexity. For example, if the goal is to capture the half-life relationship of protein degradation, a known non-linear process with exponential decay, the use of a linear model will not result in accurate prediction of protein levels at any time point, no matter how many training samples make up the dataset. By contrast, variance expresses the sensitivity of the model to small perturbations in the input. A model of high variance will provide substantially different answers (output values) for small changes in the input, because of overfitting of its parameters to the training dataset at hand [61]. This prevents generalizations (and thus the ability of the model to perform well) to other datasets never seen by the model, i.e., those it has not been trained on. In general, variance increases and bias decreases with increasing model complexity [36,62].
Many ML algorithms are susceptible to overfitting because they have a strong propensity to fit the model to the dataset and minimize the loss function as much as possible. Because the goal of ML is to make the model generalizable from learning the training data, and not to obtain the best model well-fitted for the training data, proper measures should be taken depending on the type of algorithm. The most popular solutions for overfitting are training with more data of high-quality and the least amount of noise, cross-validation, early stopping, pruning (remove features), regularization, and ensembling [36,37,61,63]. The appropriate combination should be selected depending on the purpose of the study, the characteristics and size of the dataset, and the learner type.
Feature engineering and selection
Since features describe the sample’s characteristics, more features imply a better understanding of the sample. However, in predictive modeling, too many features can impede learning because some may be irrelevant to the target of interest, less important than others or redundant in the context of other features. A “curse of dimensionality” occurs when the dimensionality of the data increases and the sparsity of the data increases [61]. It is statistically advantageous to estimate fewer parameters. In addition, researchers usually want to know the key informative features obtained with a simple model rather than work with a complex model that uses a large number of features to predict the outcome. In truth, processes that make the refined data amenable to learning, such as data cleaning, preprocessing, feature engineering and selection, are more essential than running a learner. However, this is a daunting task because it is manually tailored by domain experts in a time-consuming process [61]. Feature engineering is the process of transforming raw data such that the revised features better represent the problem that is of interest to the predictive model, resulting in improved model performance on new data. An example is to transform the counts of tender and/or swollen joints and the erythrocyte sedimentation rate (ESR) into a single formulated feature, Disease Activity Score (DAS28)-ESR, which better assesses disease activity in patients with RA. Feature selection is the process of selecting a subset of relevant features while pruning less-relevant features for use in model construction. There are three methods in feature selection algorithms: filter methods, wrapper methods, and embedded methods [37,64,65]. Filter methods involve the assignment of a score to each feature using a statistical measure followed by selection of high-ranked features based on the score. Filtering uses a preprocessing step and includes correlation coefficient scores, the pseudo-R2 statistic and information gain. Wrapper methods evaluate multiple models using procedures that add and/or remove predictors to find the optimal combination that maximizes model performance. An example is the recursive feature elimination algorithm. Embedded methods perform variable selection in the process of training and are usually specific to certain learning machines. The most common type of embedded feature-selection method is the regularization method found in LASSO, Elastic Net, and Ridge regression. The features selected from the methods do not necessarily have a causal relationship with the target label, but simply provide critical information for use in predictive model construction.
Limitations of machine learning
ML has become ubiquitous and indispensable for solving complex problems in most sciences [16]. It can present novel findings or reveal previously hidden but important features that have been missed or overlooked in conventional studies using traditional statistics. However, those features might also be irrelevant, nonsensical, counterposed to the framework of current medical knowledge, or even cause confusion. This is because the results returned by ML are based solely on the input data. ML does not call the input data into question or explain why the results were obtained or their underlying mechanism. In the event of unexpected results, the data should be re-investigated to determine whether human or technical errors have created biases, followed by careful interpretation and validation in the context of the disease.
ML models are fairly dependent on the data they are trained on or are called upon to analyze, and no model, regardless of its sophistication, can create a useful analysis from low-quality data [61,66]. As data are a product made in the past and represent existing knowledge, ML models are valid within the same framework of that knowledge and their performance will degrade if they are not regularly updated using new, emerging data. In the case of a supervised classifier, a common problem is that the classes that make up the target label are not represented equally. An imbalanced distribution of class sizes across samples favors learning weighted to the larger class size such that the trained model then preferably assigns a major class label to new instances thereof while ignoring or misclassifying minority samples, which, although they rarely occur, might be very important. Several methods have been devised to handle the imbalanced class issue [67,68].
Because the optimal algorithm, i.e., the one that best fits the data of interest, cannot be known beforehand, a reasonable strategy is to sequentially test simple and widely known learners before moving on to those that are more sophisticated and distinct. In some ML learners, hyperparameters should be tuned by exhaustively searching through a manually specified subset of the hyperparameter space of a learning algorithm [69].
Randomness is an inherit characteristic of ML applications [70], appearing in data collections, observation orders, weight assignments, and resampling, among others. To create stable, robust models with reproducible results, detailed information on the type and version of the computational tools, learners’ parameters, hyperparameters and random seed number used should always be reported [71].
ILLUSTRATIVE EXAMPLES OF MACHINE LEARNING
Several representative clinical studies in which ML methods were used in the area of internal medicine are summarized in Table 1 [72-86]. In the study of rheumatic diseases, ML has been employed only recently, but two of those studies are particularly noteworthy. In the first, Orange et al. [87] reported the identification of three distinct synovial subtypes based on the synovial gene signatures of patients with RA. These labels were used to design a histologic scoring algorithm in which the histologic scores correlated with clinical parameters such as ESR, C-reactive protein (CRP) level, and autoantibody titer [87]. The authors selected 14 histologic features from 129 synovial samples (123 RA and six osteoarthritis [OA] patients) and the 500 most variably expressed genes in 45 synovial samples (from 39 RA and six OA patients). Gene-expression-driven subgrouping was explored by k-means clustering, in which n objects are partitioned into k clusters, with each object belonging to the cluster with the nearest mean [88]. Clustering was most robust at 3 and this subgrouping was validated by principal component analysis, but not in an independent dataset. Three subgroups comprising high-inflammatory, low-inflammatory, and mixed subtypes, were designated based on their gene patterns and enriched ontology. The aim of the study was to determine the synchrony between synovial histologic features and genomic subtype, thereby yielding a convenient histology-based approach to characterization of synovial tissue. To this end, a leave-one-out cross-validation SVM classifier was implemented. The aim of an SVM is to find a decision hyperplane that separates data points of different classes with a maximal margin (i.e., the maximal distance to the nearest training data points) [89]. The model’s performance in separating both the high and the low inflammatory subtypes from the other subtypes was relatively good (AUCs of 0.88 and 0.71, respectively). It should be noted that histologic subtypes are closely associated with clinical features, as significant increases in ESR, CRP levels, rheumatoid factor titer, and anti-cyclic citrullinated protein (CCP) titer in patients with high inflammatory scores were detected. However, this model might succumb to overfitting because SVM is vulnerable to overfitting [89,90], the sample size was too small (only 45 samples) and the model was not validated using an independent dataset. Moreover, the data samples were a mixture of RA and OA samples and there were no normal controls. SVM is an unsupervised ML with an efficient performance achieved using the kernel trick and the tuning of hyperparameters. A better approach would be to specify the details of the model (kernel type, parameters, and hyperparameters) during method selection, to guarantee the reliability and reproducibility of the model.

Representative clinical studies using machine learning methods in internal medicine
In the second, Lezcano-Valverde et al. [91] developed and validated a random survival forest (RSF) prediction model of mortality in RA patients based on demographic and clinically related variables. RSF, an extension of random forest for time-to-event data, is a non-parametric method that generates multiple decision trees using a bagging method [92,93]. Bagging, an abbreviation for bootstrap aggregation, is a simple and powerful ensemble method that fits multiple predictive models on random subsets of the original dataset and aggregates their individual predictions by either voting or averaging [94]. It is commonly used to reduce variance and avoid overfitting. RSF is an attractive alternative to the Cox proportional hazards model when the proportional hazards assumption is violated [93,95]. Lezcano-Valverde et al. [91] used two independent cohorts as the training and validation datasets: the RA cohort from the Hospital Clínico San Carlos (HCSC-RAC), consisting of 1,461 patients, and the 280 RA patients from the Hospital Universitario de La Princesa Early Arthritis Register Longitudinal (PEARL) study. Each model was run 100 times using 1,000 trees per run. The prediction error was 0.187 in the training cohort and 0.233 in the validation cohort. Important variables with a higher predictive capacity were age at diagnosis, median ESR and number of hospital admissions. These variables were consistent with those obtained in a previous result using a Cox proportional hazards model [96]. The strengths of the approach described in that study were external validation using an independent RA cohort and the absence of a restrictive assumption, which traditional Cox proportional hazards model rely on. RSF has also been used to analyze the mortality risk in patients with systemic lupus erythematosus [97] and in those with juvenile idiopathic inflammatory myopathies [98].
CONCLUSIONS
ML algorithms can accommodate diverse configurations of data, specify context weighting, and identify informative patterns that enable subgrouping or predictive modeling from every interaction of variables available for the assessment of diagnostic and prognostic elements. Extensive, in-depth applications of ML in biomedical science are increasing in number, and interesting results in the area of precision medicine have been obtained. However, several challenges must still be overcome. First, ML works only if the training data are representative of the problem to be solved, include informative features and are of sufficient quantity to train the model at hand. This can be difficult to achieve for both technical and real-world reasons. Second, privacy is a major concern in the collection of sensitive clinical data, which might limit the aggregation of all necessary information. Moreover, some data are expensive to acquire, reported in different formats and obtained using different methods and technologies. Third, because text-based medical records can be incoherent, distracted, and contain technical errors [52,53], expert human judgement is needed to review the data, detect any errors or problems and determine the clinical significance of any findings [35,99]. Finally, a consensus should be reached on how to integrate and coordinate ML results with previously established guidelines or recommendations that were based on traditional statistics.
ML and AI will change the clinical landscape as we know it. From clinical decision support tools and personalized recommendation systems to the discovery of novel drugs and treatments, AI is poised to propel our world to unprecedented levels of automation, personalized service and accelerated R&D cycles. Close collaboration and interdisciplinary teamwork between clinicians, biomedical informatics scientists, ML experts, and administrative stakeholders are a prerequisite to the achievement of satisfactory solutions amenable to a variety of clinical applications.
Notes
No potential conflict of interest relevant to this article was reported.